
Organiser: Daniel Chicharro
If you wish to attend, via Zoom, please click the envelope to contact the Seminar Organisers
Year 2024-25
- Tuesday, 22-04-2025 (AG04, Zoom, 16:00): Seminar by Marin Lujak (Artificial Intelligence Research Group, Escuela Técnica Superior de Ingeniería Informática), at Universidad Rey Juan Carlos.
Scalable, efficient and distributed multi-agent coordination of automated agricultural vehicle fleets
Agriculture faces a threefold challenge: producing enough food for a growing global population, ensuring the economic and environmental sustainability of farming, and addressing labor shortages for dangerous, repetitive tasks. Agricultural robotics offers a path forward by uniting eco-preservation with increased productivity through precision and reliability. In this talk, we explore distributed multi-agent coordination of heterogeneous agricultural robot fleets, focusing on approaches that enable autonomous, scalable, and real-time operations without relying on a centralized control center. We will delve into advanced solution methods for the three-index assignment problem and the dynamic vehicle routing problem, highlighting how these methods allow fleets to adapt seamlessly to changing conditions and tasks while minimizing human intervention. Our discussion emphasizes the role of distributed optimization and multi-agent systems in balancing individual agent objectives with overall system performance. We will describe models and architectures for task allocation and vehicle routing, underscoring distributed algorithms that promote fairness and efficiency at both local and global levels. Finally, we will showcase how recent advances in digital twins empower agri robot coordination, and we will illustrate how these methods can be applied to manage autonomous agricultural robot fleets in cooperative settings.
To watch this seminar video recording, click the thumbnail below
- Wednesday, 11-12-2024 (AG04, Zoom, 15:00): Seminar by Alberto Fernández (Artificial Intelligence Research Group, Escuela Técnica Superior de Ingeniería Informática), at Universidad Rey Juan Carlos.
Value-aligned decision making
Engineering intelligent systems that are aware of human values and adopt them in their decision-making processes is a research topic that has attracted attention in the last few years. In this talk, we will discuss two different problems in this context. First, a model that allows agents to make decisions aligned with their value systems will be presented. The model considers how important different values are for the agent as well as how much a given action promotes or demotes a certain value. Motivated by psychological theories (e.g. Schwartz’s basic values theory), the model considers the interaction of different values in a value system. Then, we will address a different problem: learning a value system from observing an agent’s behaviour. We propose a formal model of the value system learning problem, which is applied to sequential decision-making domains based on multi-objective Markov decision processes. Inverse reinforcement learning is used to infer value groundings and value systems.
To watch this seminar video recording, click the thumbnail below
- Wednesday, 30-10-2024 (Room AG07b, Zoom, 16:00): Seminar by Michael Akintunde (Department of Computer Science) at City St George's, University of London.
Towards the development of trustworthy autonomous systems
Humans are increasingly interacting with autonomous systems. It is becoming common for such systems to contain components driven by software generated by machine learning techniques which are difficult to reason about. It is fundamental that humans in contact with such systems can be provided with assurances of their behaviour and that these systems are designed in a way to foster trust, to develop symbiotic human-AI partnerships. Formal verification is one way to achieve this; we will discuss ways to tackle the verification problem for systems with components learned through data using machine learning and implemented with neural network components. Another direction is to consider the human element; there is a need also to establish the trustworthiness of autonomous systems from a human perspective. We will discuss techniques ranging from taking a formal perspective to specifying trust, to considering the insights gained from user studies with human subjects when interacting with autonomous systems.
Year 2023-24
- Wednesday, 12-06-2024 (Zoom; 16:00): Seminar by Mel Andrews (Department of Philosophy) at University of Cincinnati and (Machine Learning Department) at Carnegie Mellon University.
What’s scientific representation got to do with responsible AI?
Philosophers have long debated how the conceptual tools of science—mostly mathematics—represent the phenomena we use them to investigate. On the surface, this seems to have little to do with issues of how machine learning based technologies are wielded to potentially harmful effect on real-world populations. I argue that it is of immediate practical relevance. Like other mathematical representations, I submit that data, trained models, and their outputs only signify aspects of reality in virtue of human interpretation. In applied/deployed ML, however, this interpretive work is often left implicit. The discovery of a generalisable pattern and thus the achievement of high classifier accuracy is frequently taken as evidence of a researchers’ unspoken background hypothesis. A widespread belief that data, models, and their outputs discover objective or ground truth without the need for human input supports such practices. I look to a recent resurgence of physiognomy-like research practices, assisted by deep learning, as a case study in the connection between epistemic confusions and ethical harms with ML.
To watch this seminar video recording, click the thumbnail below
-
Thursday, 30-05-2024 (On Campus AG03 and Zoom; 16:00): Seminar by Giorgos Kordopatis-Zilos (Visual Recognition Group, Faculty of Electrical Engineering) at Czech Technical University in Prague.
Visual similarity learning with local representations
Estimating visual similarity between pairs of media (i.e., images or videos) is one of the cornerstones of many Computer Vision applications. In the Deep Learning era, global representations for the media items are typically extracted using a deep neural network, combined with simple similarity metrics (e.g., cosine similarity) to estimate similarity. This approach is prone to clutter/noise that is aggregated into the global representations, leading to inaccurate estimations. A different avenue is to leverage local representations of the internal parts that compose the media items (i.e., image regions or video frames) and train neural networks via similarity learning to precisely estimate similarity. Hence, in this talk, we will explore the advancements in the literature to answer the following questions: (i) How do we extract local representations of our media items? (ii) How can we estimate the similarity between two sets of local representations using neural networks?
First, we will focus on the extraction of local representations and review popular region pooling functions applied to image feature maps generated by deep models. Recent local feature detector networks trained to detect informative local descriptors will also be revisited. Then, we will go through the state-of-the-art approaches to estimate visual similarity in the image and video domain. Proposed solutions employ popular neural network architectures, such as Convolutional Neural Networks and Transformers, and rely on various training schemes for similarity learning using supervision, self-supervision, or knowledge distillation. Finally, we will compare the different methods on the popular benchmark datasets and discuss practical ways of combining local and global similarity to achieve the optimal trade-off between performance and efficiency.
To watch this seminar video recording, click the thumbnail below
-
Wednesday, 01-05-2024 (On Campus and Zoom; 16:00): Seminar by Enrico Liscio (Interactive Intelligence Group) at Faculty Electrical Engineering, Mathematics and Computer Science, TU Delft.
Context-Specific Value Inference via Hybrid Intelligence
Human values, e.g., benevolence and self-determination, are the abstract motivations that drive our opinions and actions. AI agents ought to align their behavior with our value preferences to co-exist with us in our society. However, value preferences differ across individuals and are dependent on context. To reflect diversity in society and to align with contextual value preferences, AI agents must be able to discern the value preferences of the relevant individuals by interacting with them. We refer to this as the value inference challenge, which is the focus of this talk. Value inference entails several challenges, and the related work is scattered across different AI subfields, from NLP to multiagent systems. We present a comprehensive overview of the value inference process by breaking it down into three distinct steps (value identification, classification, and estimation), introducing the related challenges and the methods we developed to address them. However, we recognize that relying solely on AI methods to infer values may not yield accurate estimates, due to the implicit nature of human value preferences. Humans must be actively engaged for a successful value inference. To this end, we propose a Hybrid Intelligence (HI) vision where human and artificial intelligence complement each other during the value inference process. We then introduce an HI approach that fosters self-reflection on values by connecting value classification and estimation. We conclude by describing several applications that are being developed based on value inference, ranging from support for deliberative policy-making to behavior change for diabetes patients.
To watch this seminar video recording, click the thumbnail below
Slides (.pdf) available here
-
Thursday, 21-03-2024 (On Campus and Zoom; 16:00): Seminar by Bradley C. Love (Department of Experimental Psychology) at the University College London and at The Alan Turing Institute.
Taming the neuroscience literature with explanatory and predictive models
Models can help scientists make sense of an exponentially growing literature. In the first part of the talk, I'll focus on process models, which carry out a task in the same manner we believe people do. Process models play an explanatory role by bridging behaviour and brain measures. I'll discuss work using process models to help understand the relationship between concept and spatial learning, considering how high-level constructs in process models can be decomposed to the level of cells to offer multi-level theories of brain and behaviour. In the second part of the talk, I will discuss using models as tools to help experimentalists design the most informative studies. For instance, the BrainGPT.org project uses large language models (LLMs) as generative models of the scientific literature. On a benchmark that involves predicting experimental results from methods, we find that LLMs exceed the capabilities of human experts. Because the confidence of LLMs is calibrated, they can team with neuroscientists to accelerate scientific discovery. I'll end by noting the complementary roles explanatory and predictive models play.
To watch this seminar video recording, click the thumbnail below
-
Thursday, 08-02-2024 (On Campus and Zoom; 16:00): Seminar by Bruno Gavranović (Mathematically Structured Programming Group) at the University of Strathclyde.
Category Theory ∩ Deep Learning : Where are we, and where can we go?
Despite its remarkable success, deep learning is a young field. Like the early stages of many scientific disciplines, it is permeated by ad-hoc design decisions. From the intricacies of the implementation of backpropagation, through new and poorly understood phenomena such as double descent, scaling laws or in-context learning, to a growing zoo of neural network architectures — there are few unifying principles in deep learning, and no uniform and compositional mathematical foundation. Having recently submitted a PhD thesis on this topic, I will give an overview of the state of the art of category-theoretic approaches to understanding Deep Learning, as well as an overview of fruitful research avenues, and my outlook on the future of Categorical Deep Learning.
To watch this seminar video recording, click the thumbnail below
-
Wednesday, 06-12-2023 (AG11 and Zoom; 16:00): Seminar by Christos Tzelepis (Artificial Intelligence Research Centre, CitAI) at City, University of London.
Controlling Generative Adversarial Networks (GANs) for Computer Vision tasks
During recent years, Generative Adversarial Networks (GANs) have emerged as a leading generative learning paradigm, exhibiting unprecedented performance in the synthesis of realistic and aesthetically pleasing images. However, despite their generative efficiency, GANs do not provide an inherent way of comprehending or controlling the underlying generative factors. The ability to understand and, thus, control the generative process can pave the way for the exploitation of the aforementioned generative ability towards tasks beyond the generative regime. Controllable generation finds application in a wide range of computer vision tasks, such as context-aware image editing, face anonymization, and neural face reenactment.
To watch this seminar video recording, click the thumbnail below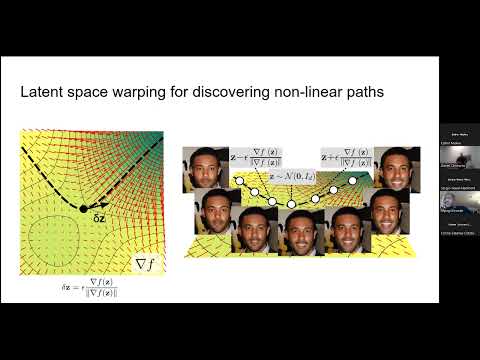
-
Wednesday, 08-11-2023 (AG11 and Zoom; 16:00): Seminar by Marc Serramià Amorós (Artificial Intelligence Research Centre, CitAI) at City, University of London.
Value alignment for multiagent systems and decision making
Normative multiagent systems use norms to coordinate their agents, this is a familiar paradigm as human societies are also governed by (legal and social) norms. However, how should we choose norms? The literature has focused mainly on the well-functioning of the multiagent system (e.g. creating norms that avoid conflicts) or other engineering requirements (e.g. that the norms are few and easy to process). However, with the raising concern over ethics and AI, another point to consider when designing norms are their ethical implications, which have been largely overlooked. Norms may promote or demote different moral values, by composing sets of norms aligned with our human values and preferences we can ensure that when agents follow the norms they will act in a value aligned way. Therefore, this selection process must consider how norms relate to moral values as well as the society's value preferences, so that the chosen norms (the so-called norm system) are those that align best with these preferences. Using optimisation and social choice techniques we can transform the initial human moral value preferences into preferences over norms which can then be used to compose a value aligned set of norms. Interestingly, the generality of these methods allows to adapt them not only to policymaking but to many other ethical reasoning and decision making problems.
To watch this seminar video recording, click the thumbnail below
Year 2022-23
-
Wednesday, 03-05-2023 (Zoom; 16:00): Seminar by Larissa Albantakis (Center for Sleep and Consciousness) at the University of Wisconsin-Madison.
Why function isn't everything when it comes to agency, autonomy, and consciousness
Should the internal structure of a system matter when it comes to autonomy? What is an agent in the first place and how do we distinguish it from its environment? When subsystems within a larger system are characterized by physical, but also biological, or informational properties, their boundaries are typically taken for granted and assumed as given. In addition, agents are supposed to act upon their environment in an autonomous manner. But can we formally distinguish autonomous actions from mere reflexes? Here, I will address these issues in light of the causal framework of integrated information theory (IIT), which provides the tools to reveal causal borders within larger systems and to identify the causes of an agent's actions. The agents under study are evolvable artificial neural networks whose connectivity and node functions adapt over the course of their evolution. Moreover, IIT has originally been conceived as a theory of consciousness. As functional equivalence between biological brains and computers seems within reach, striking differences remain regarding their respective problem-solving algorithms, implementation, and causal structures. But causal structure, and thus implementation, matters for delineating the borders of a system from its environment, and for identifying whether the system under observation is in fact one system as opposed to multiple. Two systems with equivalent behavior may thus still differ in their capacity for autonomy, agency, and consciousness.
To watch this seminar video recording, click the thumbnail below
-
Wednesday, 29-03-2023 (Zoom; 16:00): Seminar by Manuel Molano-Mazón (the Computational Neuroscience Group) at Mathematics Research Centre.
Recurrent networks endowed with structural priors explain suboptimal animal behavior
The strategies found by animals facing a new task are determined both by individual experience and by structural priors evolved to leverage the statistics of natural environments. Rats quickly learn to capitalize on the trial sequence correlations of two-alternative forced choice (2AFC) tasks after correct trials but consistently deviate from optimal behavior after error trials. To understand this outcome-dependent gating, we first show that recurrent neural networks (RNNs) trained in the same 2AFC task outperform rats as they can readily learn to use across-trial information both after correct and error trials. We hypothesize that, although RNNs can optimize their behavior in the 2AFC task without any a priori restrictions, rats’ strategy is constrained by a structural prior adapted to a natural environment in which rewarded and non-rewarded actions provide largely asymmetric information. When pre-training RNNs in a more ecological task with more than two possible choices, networks develop a strategy by which they gate off the across-trial evidence after errors, mimicking rats’ behavior. Population analyses show that the pre-trained networks form an accurate representation of the sequence statistics independently of the outcome in the previous trial. After error trials, gating is implemented by a change in the network dynamics that temporarily decouple the categorization of the stimulus from the across-trial accumulated evidence. Our results suggest that the rats’ suboptimal behavior reflects the influence of a structural prior that reacts to errors by isolating the network decision dynamics from the context, ultimately constraining the performance in a 2AFC laboratory task.
To watch this seminar video recording, click the thumbnail below
-
Wednesday, 01-03-2023 (Zoom; 16:00): Seminar by Laura Driscoll (Neural Prosthetic Systems Lab (NPSL)) at Wu Tsai Neurosciences Institute Stanford University.
How are multiple computations organized within a single network?
Flexible computation is a hallmark of intelligent behavior. Yet, little is known about how neural networks contextually reconfigure for different computations. Humans are able to flexibly perform novel tasks without extensive training, presumably through the composition of elementary processes that were previously learned. Cognitive scientists have long hypothesized the possibility of a compositional neural code, where complex neural computations are made up of constituent components; however, the neural substrate underlying this structure remains elusive in biological and artificial neural networks. We identified an algorithmic neural substrate for compositional computation through the study of multitasking artificial recurrent neural networks. Dynamical systems analyses of networks revealed learned computational strategies that mirrored the modular subtask structure of the task-set used for training. Dynamical motifs such as attractors, decision boundaries and rotations were reused across different task computations. For example, tasks that required memory of a continuous circular variable repurposed the same ring attractor. We show that dynamical motifs are implemented by clusters of units and are reused across different contexts, allowing for flexibility and generalization of previously learned computation. Lesioning these clusters resulted in modular effects on network performance: a lesion that destroyed one dynamical motif only minimally perturbed the structure of other dynamical motifs. Finally, modular dynamical motifs could be reconfigured for fast transfer learning. After slow initial learning of dynamical motifs, a subsequent faster stage of learning reconfigured motifs to perform novel tasks. This work contributes to an understanding of how compositional computation could be implemented for flexible general intelligence in neural systems. We present a conceptual framework that establishes dynamical motifs as a fundamental unit of computation, intermediate between the neuron and the network. This framework will provide a novel perspective for the study of learning and memory in continuously evolving neural dynamical systems.
This seminar will not be recorded
-
Wednesday, 11-01-2023 (Zoom; 16:30): Seminar by Ryan-Rhys Griffiths at Meta Research.
GAUCHE: A Library for Gaussian Processes in Chemistry
GAUCHE is a library for GAUssian processes in CHEmistry. Gaussian processes have long been a cornerstone of probabilistic machine learning, affording particular advantages for uncertainty quantification and Bayesian optimisation. Extending Gaussian processes to chemical representations however is nontrivial, necessitating kernels defined over structured inputs such as graphs, strings and bit vectors. By defining such kernels in GAUCHE, we seek to open the door to powerful tools for uncertainty quantification and Bayesian optimisation in chemistry. Motivated by scenarios frequently encountered in experimental chemistry, we showcase applications for GAUCHE in molecular discovery and chemical reaction optimisation. The codebase is made available at
https://github.com/leojklarner/gauche
To watch this seminar video recording, click the thumbnail below
-
Wednesday, 07-12-2022 (Zoom; 16:00): Seminar by Tim Albrecht (School of Chemistry) at the University of Birmingham.
Event (Anomaly) Detection in Single-Molecule Resistive Pulse Sensing Data – enhancing experimental capabilities with AI
Resistive pulse sensors are devices capable of label-free, electric detection of individual molecules such as proteins and DNA. At their heart is a small, nanometre-sized channel (the “nanopore”) and whenever an analyte passes through this channel, its electric resistance and hence the measured current through the device change. These molecular events are relatively rare and short occurrences in long traces of current-time data. They appear at random times, due to the stochastic nature of transport towards the nanopore. High temporal resolution is key to detecting small analytes (proteins) or to resolving structural features in long pieces of DNA (knots or loops). This means that measurements are performed at the highest possible bandwidth – typically, in the 100s kHz range – even if that results in poor signal-to-noise ratio (S/N). In the field, event detection is most commonly done via amplitude threshold searches. However, to maintain a reasonable compromise between true and false positive events, the S/N has to be at least 2-3, thereby limiting the bandwidth and time resolution in any given experiment. In order to overcome or at least mitigate these challenges, we have experimented with alternative approaches to event detection, including zero-crossing theory and the use of neural networks. The latter in particular has proven rather successful, at least with realistic synthetic data. For example, by combining a convolutional autoencoder with change point detection, we were able to obtain true positive rates of larger than 70% for S/N as low as 0.5. From an experimental point of view, this implies that much higher noise levels may be tolerated with an estimated tenfold increase in bandwidth and time resolution. In future work, we will test this framework with experimental data, where establishing the “ground truth” poses its own challenges.
To watch this seminar video recording, click the thumbnail below
Year 2021-22
-
Wednesday, 06-07-2022 (Zoom; 16:30): Seminar by Catia Pesquita (LASIGE Computer Science and Engineering Research Centre) at the Universidade de Lisboa.
Holistic Knowledge Graphs for AI in biomedicine
Biomedical AI applications increasingly rely on multi-domain and heterogeneous data, especially in areas such as personalised medicine and systems biology. Biomedical Ontologies and Knowledge Graphs are a golden opportunity in this area because they add meaning to the underlying data which can be used to support heterogeneous data integration, provide scientific context to the data augmenting AI performance, and afford explanatory mechanisms allowing the contextualization of AI predictions. This talk focuses on my recent work on building holistic knowledge graphs based on the semantic integration of clinical and biomedical data across domains, and how they can be explored to improve, augment and explain artificial intelligence applications.
To watch this seminar video recording, click the thumbnail below
-
Wednesday, 25-05-2022 (Zoom; 17:30): Seminar by Erkan Buzbas (Department of Mathematics and Statistical Science) and Berna Devezer (College of Business and Economics) at the University of Idaho.
Mathematical, statistical, and agent-based modeling of scientific process and results reproducibility
Low rates of results reproducibility observed in some scientific areas is a poorly understood phenomenon from the perspective of mathematical and statistical modeling of scientific process. We investigate this problem using a model system of science. In this talk, our goal is twofold: First, we aim to compare diverse modeling approaches to find a suitable and flexible modeling framework to study the determinants and consequences of results reproducibility. We will elaborate the pros and cons of different modeling approaches. A classical Markov Chain model grants us interpretability and clarity of theoretical results but may be considered too simplistic. An agent-based modeling framework provides higher flexibility but creates difficulties in establishing theoretical results. Second, to illustrate the uses and difficulties of these approaches we will introduce a model system of science in which scientists adopt a model-centric approach to discover the true model generating data in a stochastic process of scientific discovery. We will present results from this model, exploring the effects of research strategies represented in the scientific population, scientists’ choice of methodology, the complexity of truth, and the strength of signal. We illustrate how the scientific process may not converge to truth even if scientific results are reproducible and how the scientific community may fail to reproduce true results.
To watch this seminar video recording, click the thumbnail below
- Wednesday, 11-05-2022 (Zoom; 16:30): Seminar by Michela Paganini (DeepMind).
Building and Understanding Language Models at Scale
We explore the scaling frontier of language modeling, with an eye towards the importance of data, experimentation with techniques for fast training and inference, and sparse computation solutions such as routing networks. Concrete examples will highlight interesting emergent behaviors, their relationship with scale, and the importance of deriving scaling laws in grounding and guiding future research.
This seminar will not be recorded
- Wednesday, 06-04-2022 (Zoom; 16:30): Seminar by Carles Sierra (Artificial Intelligence Research Institute, CSIC).
Value-engineering
Ethics in Artificial Intelligence is a wide-ranging field which encompasses many open questions regarding the moral, legal and technical issues that arise with the use and design of ethically-compliant autonomous agents. In this talk, I’ll focus on the engineering of moral values into autonomous agents. I’ll discuss an approach where values are interpreted as permanent goals and norms as the means to promote those values. Then, I will describe a systematic methodology for the synthesis of parametric normative systems based on value promotion that constitutes a practical method for value-engineering.
To watch this seminar video recording, click the thumbnail below
- Wednesday, 09-03-2022 (Zoom; 17:30): Seminar by Stefano Ghirlanda (Brooklyn College, City University of New York and Stockholm University).
From Associations to Probabilities
Theories of animal learning are traditionally expressed in terms of associations between internal representations of events, such as conditioned and unconditioned stimuli in Pavlovian conditioning. Recently, however, researchers have explored the idea that animal learning is best understood rationally, for example, in terms of Bayesian inference or information theory.
I am exploring how to reconcile the two approaches, which would lead to an understanding how relatively simple associative systems might perform relatively complex probabilistic computations. As an example, I show that an associative system can perform exact inference by using the function f(V)=1-exp(-kV) to transform associative strengths (V) into probabilities. For example, using this function, an associative system can correctly infer the probability that a compound stimulus AB will be reinforced, given the probabilities that A and B are reinforced when experienced each on its own.
More generally, the probability formulae that result from this approach agree with statistical decision theory. The formulae also suggest a rational interpretation of stimulus generalization as a heuristic to infer whether different stimuli are likely to convey redundant or independent information about reinforcement.
To watch this seminar video recording, click the thumbnail below
- Wednesday, 23-02-2022 (Zoom; 16:30): Seminar by Melanie Mitchell (Santa Fe Institute).
Why AI is Harder Than We Think
Since its beginning in the 1950s, the field of artificial intelligence has cycled several times between periods of optimistic predictions and massive investment (“AI Spring”) and periods of disappointment, loss of confidence, and reduced funding (“AI Winter”). Even with today’s seemingly fast pace of AI breakthroughs, the development of long-promised technologies such as self-driving cars, housekeeping robots, and conversational companions has turned out to be much harder than many people expected. One reason for these repeating cycles is our limited understanding of the nature and complexity of intelligence itself. In this talk I will discuss some fallacies in common assumptions made by AI researchers, which can lead to overconfident predictions about the field. I will also speculate on what is needed for the grand challenge of making AI systems more robust, general, and adaptable—in short, more intelligent.
To watch this seminar video recording, click the thumbnail below
- Wednesday, 26-01-2022 (Zoom; 16:30): Seminar by David Filliat (ENSTA Paris).
Improving data efficiency for machine learning in robotics
Machine learning is a key technology for robotics and autonomous systems, in the area of sensory processing and in the area of control. While learning on large datasets for perception lead to impressive applications, applications in the area of control still present many challenges as the system to control remains slow and brittle. Reducing the required number of interactions with the system is, therefore, a key aspect of the progress of machine learning applied to robotics. We will present different approaches that can be used for this purpose, in particular approaches for State Representation Learning that can help improve data efficiency in Reinforcement Learning.
To watch this seminar video recording, click the thumbnail below
- Wednesday, 08-12-2021 (Zoom; 16:30): Seminar by Ira Ktena (DeepMind).
Graph representations and algorithmic transparency in life sciences
Graphs are omnipresent in life sciences. From the molecular structures of drug compounds to the cell signaling networks and brain connectomes, leveraging graph structural information can unlock performance improvements and provide insights for various tasks, where data inherently lies in irregular domains. In this talk I'm going to cover the immense potential of graph representation learning in life sciences and some of the state-of-the-art approaches that have shown great progress in this domain. The talk will further cover aspects of algorithmic transparency and how these considerations might arise in the context of life sciences.
We are sorry to announce that this seminar's video will not be available. DeepMind has not authorised its release. - Wednesday, 24-11-2021 (Zoom; 16:30): Seminar by Shuhui Li (Department of Electrical and Computer Engineering at The University of Alabama).
Neural-Intelligence for IPM Motor Control and Drives in Electric Vehicles
Due to the limited space within an electric vehicle (EV), high performance and efficiency of EV electric and electronic components are critical in accelerating the growth of the EV market. One of the most important components within an EV is electric motors, particularly the widely used interior-mounted permanent magnet (IPM) motor by the automobile industry. This seminar focuses on the development of multiple Neuro-Intelligence (NI) systems to overcome the technological limitations in existing IPM motor drives and control systems to improve motor efficiency and reliability. The design of the NI systems will employ a closed-loop interaction between data-driven NI methods and physics-based models and principles as much as possible to enhance the learning ability of the NI systems that can meet the real-life requirements and conditions. To handle the part-to-part variation of individual motors and ensure the lifetime adaptivity and learning capabilities of the offline-trained NI systems, a 5G-based cloud computing platform is employed for routine offline NI learning after an EV is put in use, which guarantees the reliability, convergence, and performance of the routine offline NI learning over the clouding computing platform for the most efficient and reliable drives of an IPM motor over its lifetime.
To watch this seminar video recording, click the thumbnail below
- Wednesday, 20-10-2021 (Zoom; 16:30): Seminar by Haitham Bou Ammar (Huawei Research & Innovation and Computer Science, UCL).
High-Dimensional Black-Box Optimisation in Small Data Regimes
Many problems in science and engineering can be viewed as instances of black-box optimisation over high-dimensional (structured) input spaces. Applications are ubiquitous, including arithmetic expression formation from formal grammars and property-guided molecule generation, to name a few. Machine learning (ML) has shown promising results in many such problems (sometimes) leading to state-of-the-art results. Abide those successes, modern ML techniques are data-hungry, requiring hundreds of thousands if not millions of labelled data. Unfortunately, many real-world applications do not enjoy such a luxury -- it is challenging to acquire millions of wet-lab experiments when designing new molecules. This talk will elaborate on novel techniques we developed for high-dimensional Bayesian optimisation (BO), capable of efficiently resolving such data bottlenecks. Our methods combine ideas from deep metric learning with BO to enable sample efficient low-dimensional surrogate optimisation. We provide theoretical guarantees demonstrating vanishing regrets with respect to the true high-dimensional optimisation problem. Furthermore, in a set of experiments, we confirm the effectiveness of our techniques in reducing sample sizes by acquiring state-of-the-art logP molecule values utilising only 1% labels compared to previous SOTA.
To watch this seminar video recording, click the thumbnail below
- Wednesday, 06-10-2021 (Zoom; 16:30): Seminar by Greg Slabaugh (Digital Environment Research Institute - DERI at Queen Mary, University of London and The Alan Turing Institute).
Capturing the Moment: Deep Learning for Computational Photography
Recently smartphones have included onboard processors capable of running deep neural networks. This has enabled the use of on-device deep learning for computational photography applications to produce high quality photographs and has spurred research interest to advance quality of photos using advanced techniques. This talk will present some recent research using convolutional neural networks for image enhancement including color and brightness transformations and bokeh, as well as a new method for adaptively training fully convolutional networks.
To watch this seminar video recording, click the thumbnail below
Year 2020-21
- Wednesday, 05-05-2021 (Zoom; 16:30): Seminar by Alex Ter-Sarkisov (CitAI at City, University of London).
Detection and Segmentation of Lesions in Chest CT Scans for The Prediction of COVID-19
We introduce a lightweight model based on Mask R-CNN with ResNet18 and ResNet34 backbone models that segments lesions and predicts COVID-19 from chest CT scans in a single shot. The model requires a small dataset to train to achieve a 42.45 average precision (main MS COCO criterion) on the segmentation test split, 93.00% COVID-19 sensitivity and F1-score of 96.76% on the classification test split across 3 classes: COVID-19, Common Pneumonia and Control/Negative.
To watch this seminar video recording, click the thumbnail below
- Wednesday, 21-04-2021 (Zoom; 16:30): Seminar by Khurram Javed (RLAI Lab at University of Alberta).
Towards Scalable Real-time Learning for making Robust Intelligent Systems
In this seminar, I will talk about the necessity of real-time learning for building robust learning systems. I will contrast two directions for making robust systems — (1) zero-shot out-of-distribution generalization and (2) real-time online adaptation — and argue that the latter is a more promising strategy. I will then talk about three open problems that have to be solved for real-time learning, namely (1) catastrophic forgetting, (2) online agent-state construction, and (3) discovery, and share some of the research being done by me and my colleagues to address these problems.
To watch this seminar video recording, click the thumbnail below
- Wednesday, 31-03-2021 (Zoom; 16:30): Seminar by Emmanuel Pothos (Department of Psychology at City, University of London).
Why should we care about 'quantum' in cognition
A predominant approach to modelling cognition is based on classical (Bayesian) probability theory. So-called Bayesian cognitive models have been consistently successful, but equally there have been instances of persistent divergence between such models and human behaviour. For example, the influential research programme from Tversky and Kahneman has produced several apparent fallacies. Probabilistic theory is not restricted to Bayesian theory, however. We explore the applicability and promise of quantum probability theory in understanding behaviour. Quantum theory is the probability rules from quantum mechanics, without any of the physics; it is in principle applicable in any situation where there is a need to quantify uncertainty. Quantum theory incorporates features, such as interference and contextuality, which appear to align well with intuition concerning human behaviour, at least in certain cases. We consider some notable quantum cognitive models.
To watch this seminar video recording, click the thumbnail below
- Wednesday, 17-03-2021 (Zoom; 16:30): Seminar, by Sergio Naval Marimont (Department of Computer Science at City, University of London).
Unsupervised approaches for medical anomaly detection
Deep learning methods have been proposed to automatically localize anomalies in medical images. Supervised methods achieve high segmentation accuracies, however, they rely on large and diverse annotated datasets and they are specific to the anomalies previously annotated. Unsupervised methods are not affected by these limitations, however, performance is comparatively poorer. Most commonly, unsupervised anomaly detection methods are based on two steps: 1) Use a generative model to learnt the distribution of normal / healthy anatomies in images 2) Localize anomalies in test images as differences from the learnt normal distribution. Anomaly Scores propose alternative ways to measure and identify the differences to the learnt distribution. During the seminar we will review the unsupervised models most commonly evaluated in the literature (namely, Variational Auto-Encoders and Generative Adversarial Networks) and strengths and weaknesses of these models for the anomaly detection task. We will also review several methods proposed to overcome these models' limitations and how they defined anomaly scores. We will finalize with a review of several studies comparing performance of these methods in Brain MR images. Slides (.pdf) available here
To watch this seminar video recording, click the thumbnail below
- Wednesday, 03-03-2021 (Zoom; 16:30): Seminar, by Indira L. Lanza Cruz (Departament de Llenguatges i Sistemes Informàtics at Universitat Jaume I).
Author Profiling for Social Business Intelligence
This research presents a novel and simple author profiling method applied to social media to classify users based on analysis perspectives for Social Business Intelligence (SBI). To demonstrate the approach, we use data from the Twitter social network over the automotive domain. Unlike most of the methods for author profiling in social media that mainly rely on metrics provided by Twitter such as followers, retweets, etc., the technique developed uses only the textual information of user profiles. One of the greatest difficulties that analysts face when addressing machine learning problems is the complexity to quickly obtain a dataset rich in data and quality. In this sense, we propose a semi-automatic technique for obtaining language models for the classification of profiles in social media oriented to SBI, based on the identification of key bi-grams. This process needs to be scalable, fast, and dynamic since the needs and objectives of analysis in the company change very frequently. We evaluate three families of classifiers, namely: SVM, MLP and FastText using FastText pre-trained embeddings. The semi-supervised and unsupervised approaches yielded very good results demonstrating the efficiency of the methodology for SBI with minimal participation of the expert.
To watch this seminar video recording, click the thumbnail below
- Wednesday, 17-02-2021 (Zoom; 16:30): Seminar, by Xingang Fu (Deparment of Electrical Engineering and Computer Science at Texas A&M University Kingsville).
Deep Recurrent Neural Network Control Applied in Solar Inverters for Grid Integration
Single-phase or three-phase grid-tied converters/Inverters are widely used to integrate small-scale renewable energy sources and distributed generations to the utility grid. A novel Recurrent Neural Network (RNN) current controller is proposed to approximate the optimal control and overcome the problems associated with conventional controllers under practical conditions. The training of the neural controllers was implemented by Levenberg-Marquardt Backpropagation (LMBP) and Forward Accumulation Through Time (FATT) algorithms efficiently. The local stability and local convergence were investigated for neural controllers to guarantee stable operations. The RNN controller was validated through a Texas Instruments (TI) LCL filter based solar microinverter kit that contains a C2000 TI microcontroller. Both simulation and hardware-in-the-loop experiments demonstrated the excellent performance of the RNN vector controller for better solar integration.
Slides (.pdf) available here
To watch this seminar video recording, click the thumbnail below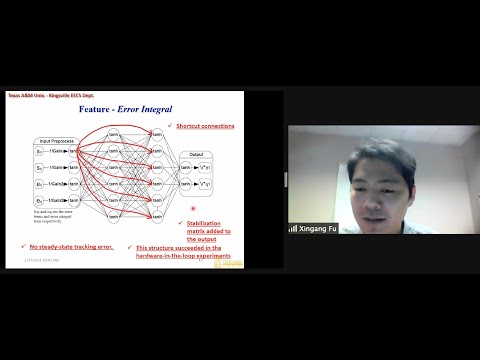
- Wednesday, 03-02-2021 (Zoom; 16:30): Seminar, by Alex Taylor (Department of Computer Science at City, University of London).
Lessons from a boy and his use of an adapted Hololens System
In this talk, I’ll come at AI/ML from a perspective that I imagine is quite unusual for CitAI presentations—from the perspective of use. Through short video clips, I’ll provide some examples of a young boy using an adapted Hololens system. We’ll learn how the boy, TH, who is blind, has come to work with others - including the system - to compose a world he is able to orientate to and interact in in new ways. The remarkable achievements that TH is able to accomplish will be shown not to be a product of the system so much as the capabilities that emerge through its use. The point I’ll aim to emphasise is that we limit the potential of actors (human or otherwise) when we define them by their individual abilities, such as whether they have sight or not. Much more generative possibilities arise when we consider how actors enable one another, through their unfolding relations. This, I’ll suggest, has wider implications for designing AI systems.
- Wednesday, 20-01-2021 (Zoom; 16:30): Seminar, by Andrea Zugarini (SAILab, Siena Artificial Intelligence Lab, at Università di Siena).
Language Modeling for Understanding and Generation
In the last decade there have been incredible advances in Natural Language Processing (NLP), where deep learning models have reached astonishing understanding and generation capabilities. Language Modeling played a major role in such developments, and nowadays Language Models (LMs) are an essential ingredient for any NLP problem. In this seminar we present how LMs are involved in text understanding and generation problems. In particular, we first describe a character-aware model to learn general purpose word and context representations that are exploitable for many language understanding tasks. Then, we outline Language Models in the context of text generation, focusing on poems. Finally, we show how language models can be a valid tool to study diachronic and dialectical language varieties.
Slides (.pdf) available here
To watch this seminar video recording, click the thumbnail below
- Wednesday, 09-12-2020 (Zoom; 16:30): Seminar, by Daniel Yon (Department of Psychology, Goldsmiths, University of London).
Prediction, action and awareness
To interact with the world around us, we must anticipate how our actions shape our environments. However, existing theories disagree about how we should use such predictions to optimise representations of our actions and their consequences. Cancellation models in action control suggest that we ‘filter out’ expected sensory signals, dedicating more resources to unexpected events that surprise us most and signal the need for further learning. In direct contrast, Bayesian models from sensory cognition suggest that perceptual inference should biased towards our prior predictions – allowing us to generate more reliable representations from noisy and ambiguous inputs. In this talk I will present a combination of psychophysical, neuroimaging (fMRI) and computational modelling work that compares these Cancellation and Bayesian models – asking how predictions generated by our actions shape perception and awareness. In light of these results, I will discuss a new hypothesis about mechanisms of prediction and surprise that may solve the ‘perceptual prediction paradox’ presented by incompatible Cancellation and Bayesian accounts.
- Wednesday, 25-11-2020 (Zoom; 16:30): Seminar, by Sebastian Bobadilla-Suarez (Love Lab, Psychology and Language Sciences, UCL).
Neural similarity in BODaviaud response and multi-unit recordings
One fundamental question is what makes two brain states similar. For example, what makes the activity in visual cortex elicited from viewing a robin similar to a sparrow? There are a number of possible ways to measure similarity, each of which makes certain conceptual commitments. In terms of information processing in the brain, interesting questions include whether notions of similarity are common across brain regions and tasks, as well as how attention can alter similarity representations. With multi-unit recordings, additional questions like the importance of spike timings can be considered. We evaluated which of several competing similarity measures best captured neural similarity. One technique uses a decoding approach to assess the information present in a brain region and the similarity measures that best correspond to the classifier’s confusion matrix are preferred. Across two published fMRI datasets, we found the preferred neural similarity measures were common across brain regions, but differed across tasks. In considering similarity spaces derived from monkey multi-unit recordings, we found that similarity measures that took into account spike timing information best recovered the representational spaces. In both fMRI and multi-unit data, we found that top-down attention, which highlighted task relevant stimulus attributes, had the effect of stretching neural representations along those axes to make stimuli differing on relevant attributes less similar. These effects were captured by a deep convolutional network front-end to a Long Short-Term Memory (LSTM) network that tracked changes in task context and whose representations stretched in a task-driven manner that paralleled patterns of neural similarity changed with task context.
To watch this seminar video recording, click the thumbnail below
- Wednesday, 18-11-2020 (Zoom; 16:30): Seminar, by Nathanael Fijalkow (LaBRI, CNRS, University of Bordeaux and The Alan Turing Institute).
Program synthesis in the machine learning era
Program synthesis is one of the oldest dream of artificial intelligence: synthesising a program from its specification, avoiding the hurdle of writing it, the pain of debugging it, and the cost of testing it. In this talk I will discuss the recent progress obtained in the field of program synthesis through the use of machine learning techniques. I will highlight the key challenges faced by the "machine learning guided search approach", and recent solutions.
To watch this seminar video recording, click the thumbnail below
- Wednesday, 11-11-2020 (Zoom; 16:30): Seminar, by Rodrigo Agerri (IXA Group, Euskal Herriko Unibertsitatea).
Word Representations for Named Entity Recognition
After a brief introduction of Information Extraction in Natural Language Processing (NLP), in this talk we will provide an overview of the most important methods to represent words in NLP and their use for the Named Entity Recognition (NER) task (extracting proper names automatically from written text). In addition to the introduction of new deep learning algorithms and architectures, new techniques for word representations have helped to greatly improve results in many NLP tasks, including NER. After introducing some of the most successful vector-based contextual representations, we will also study their impact for multilingual approaches as well as for low resourced languages, such as Basque.
Slides (.pdf) available here
To watch this seminar video recording, click the thumbnail below
- Wednesday, 28-10-2020 (Zoom; 16:30): Seminar, by Alessandro Betti (SAILab, Siena Artificial Intelligence Lab, at Università di Siena).
A Variational Framework for Laws of Learning
Many problems in learning naturally present themselves as a coherent stream of information which has its proper dynamics and temporal scales; one emblematic example is that of visual information. However nowadays most of the approaches to learning completely disregard, at all, or in first approximation, this property of the information on which the learning should be performed. As a result, the problem is typically formulated as a “static” optimization problem on the parameters that define a learning model. Formulating a learning theory in terms of an evolution laws instead shifts the attention to the dynamical behaviour of the learner. This gives us the opportunity, for those agents that live in streams of data to couple their dynamics with the information that flows from the environment and to incorporate into the temporal laws of learning dynamical constraints that we know will enhance the quality of learning. We will discuss how we can consistently frame learning processes using variational principles.
Slides (.pdf) available here
To watch this seminar video recording, click the thumbnail below
- Wednesday, 21-10-2020 (Zoom; 16:30): Seminar, by Mehdi Keramati (Department of Psychology at City, University of London).
Optimal Planning under Cognitive Constraints
When deciding their next move (e.g. in a chess game, or a cheese maze), a superhuman or a super-mouse would think infinitely deep into the future and consider all the possible sequences of actions and their outcomes. A terrestrial human or mouse, however, has limited time-consuming computational resources and is thus compelled to restrict its contemplation. A key theoretical question is how an agent can make the best out of her limited time and cognitive resources in order to make up her mind. I will review several strategies, some borrowed from the artificial intelligence literature, that we and others have demonstrated that animals/humans use in the face of different cognitive limitations. These strategies include: acting based on habits, limiting the planning horizon, forward/backward planning, hierarchical planning, and successor-representation learning.
To watch this seminar video recording, click the thumbnail below
- Wednesday, 14-10-2020 (Zoom; 16:00): Seminar by Jonathan Passerat-Palmbach (ConsenSys, and BioMedIA at Imperial College London).
Convergence of Blockchain and Secure Computing for Healthcare solutions
Web3 provides us with the bricks to build decentralised AI marketplaces where data and models could be monetised. However, this stack does not provide the privacy guarantees required to engage the actors of this decentralised AI economy. Once a data or a model has been exposed in plaintext, any mechanism controlling access to this piece of information becomes irrelevant since it cannot guarantee that the data has not leaked. In this talk, we'll explore the state-of-the-art in Secure/Blind Computing that will guarantee the privacy of data or models and enable a decentralised AI vision. Typically, we will describe an Ethereum orchestrated architecture for a technique known as Federated Learning that enables training AI models on sensitive data while respecting their owners' privacy.
To watch this seminar video recording, click the thumbnail below
- Wednesday, 07-10-2020 (Zoom; 16:30): Seminar by Yang-Hui He (Department of Mathematics at City University of London)
Universes as Bigdata: Superstrings, Calabi-Yau Manifolds and Machine-Learning
We review how historically the problem of string phenomenology lead theoretical physics first to algebraic/differential geometry/topology, and then to computational geometry, and now to data science and machine-learning. With the concrete playground of the so-called Calabi-Yau landscape, accumulated by the collaboration of physicists, mathematicians and computer scientists over the last 4 decades, we show how the latest techniques in machine-learning can help explore problems of physical and mathematical interest.
To watch this seminar video recording, click the thumbnail below
- Wednesday, 30-09-2020 (Zoom; 16:30): Seminar by Michaël Garcia-Ortiz (Department of Computer Science at City, University of London)
The illusion of space
Humans naturally experience the notion of space, which is integral to how we perceive and act in the world. In this seminar, we will ask ourselves where this notion comes from, and how it can emerge in biological and artificial agents. We will draw relations between space, objects, and actions, following ideas that Poincare expressed more than 100 years ago. Finally, we will see how predictive learning can be used as a mechanism to acquire the notions of displacement, space, and objects.
Year 2019-20
- Wednesday, 15-07-2020 (Zoom; 16:30): Seminar, by Eduardo Alonso, (CitAI and Department of Computer Science at City, University of London).
On representations, symmetries, groups, and variational principles
Given the complexity of the world, one of the main problems in Artificial General Intelligence is how to learn tractable representations. One potential solution is to assume that the world shows structure-preserving symmetries that our representations should reflect. Symmetries have been traditionally formalised as groups and, through the conservation of certain quantities, embed variational principles that dynamic laws must follow. In this talk we will try to bridge the gap between recent advances in representational learning that use group theory to express symmetries and the Free Energy Principle, which hypothesizes that the brain processes information so as to minimize surprise. Interestingly, the latter presumes that organisms execute actions intended to transform the environment in such a way that it matches our preferred representation of the world; on the other hand, it has been proposed that for the agents to learn such representations they must execute operations, as dictated by the actions of the underlying symmetry group. Once the relation between symmetries and variational principles, in the context of representational learning, has been established, we will introduce the idea that groupoids, rather than groups, are the appropriate mathematical tool to formalise partial symmetries that, we claim, are the symmetries of the real world.
Slides (.pdf) available here
- Week 7, 04-03-2020 (AG03; 16:30): Seminar, by Hugo Caselles-Dupré (ENSTA ParisTech and Softbank Robotics Europe; ObviousArt).
Re-defining disentanglement in Representation Learning for artificial agents
Finding a generally accepted formal definition of a disentangled representation in the context of an agent behaving in an environment is an important challenge towards the construction of data-efficient autonomous agents. The idea of disentanglement is often associated to the idea that sensory data is generated by a few explanatory factors of variation. Higgins et al. recently proposed Symmetry-Based Disentangled Representation Learning, an alternative definition of disentanglement based on a characterization of symmetries in the environment using group theory. In our latest NeurIPS paper we build on their work and make observations, theoretical and empirical, that lead us to argue that Symmetry-Based Disentangled Representation Learning cannot only be based on static observations: agents should interact with the environment to discover its symmetries.
Slides (.pdf) available here - Week 5, 19-02-2020 (C300; 16:30): Seminar, by Lee Harris (Computational Intelligence Group, University of Kent).
Comparing Explanations Between Random Forests And Artificial Neural Networks
The decisions made by machines are increasingly comparable in predictive performance to those made by humans, but these decision making processes are often concealed as black boxes. Additional techniques are required to extract understanding, and one such category are explanation methods. This research compares the explanations of two popular forms of artificial intelligence; neural networks and random forests. Researchers in either field often have divided opinions on transparency, and similarity can help to encourage trust in predictive accuracy alongside transparent structure. This research explores a variety of simulated and real-world datasets that ensure fair applicability to both learning algorithms. A new heuristic explanation method that extends an existing technique is introduced, and our results show that this is somewhat similar to the other methods examined whilst also offering an alternative perspective towards least-important features.
Slides (.pdf) available here - Week 4, 12-02-2020 (ELG14; 16:30): CitAI planning events 2020 (Core members).
- Week 3, 05-02-2020 (C300; 16:30): Seminar, by Vincenzo Cutrona (INSID&S Lab, Università di Milano-Bicocca).
Semantic Data Enrichment meets Neural-Symbolic Reasoning
Data enrichment is a critical task in the data preparation process of many data science projects where a data set has to be extended with additional information from different sources in order to perform insightful analyses. The most crucial pipeline step is the table reconciliation, where values in cells are mapped to objects described in the external data sources. State-of-the-art approaches for table reconciliation perform well, but they do not scale to huge datasets and they are mostly focused on a single external source (e.g., a specific Knowledge Graph). Thus, the investigation of the problem of scalable table enrichment has recently gained attention. The focus of this talk will be on an experimental approach for reconciling values in tables, which relies on the neural-symbolic reasoning paradigm and that is potentially able to both scale and adapt itself to new sources of information. Preliminary results will be discussed in the last part of the talk.
Slides (.pdf) available here - Week 2, 29-01-2020 (C321; 15:00): Worktribe session, by Claudia Kalay (Research & Enterprise Office) (Core members).
- Week 1, 22-01-2020 (ELG14; 16:10): CitAI funding strategy 2020 (Core members).
- Week 11, 04-12-2019 (E214): EIT and other R&E opportunities, by Brigita Jurisic (Research & Enterprise Office) (Core members).
- Week 10, 27-11-2019 (AG04): Lecture on Deep Learning II, by Alex Ter-Sarkisov (Core members).
- Week 9, 20-11-2019 (A227): Seminar, by Kizito Salako, Sarah Scott, Johann Bauer and Nathan Olliverre.
- Week 8, 13-11-2019 (E214): Lecture on Deep Learning I, by Alex Ter-Sarkisov (Core members).
- Week 7, 06-11-2019 (AG11): Seminar, by Fatima Najibi, Tom Chen, Alex Ter-Sarkisov, and Atif Riaz.
- Week 5, 23-10-2019 (ELG14): Knowledge Transfer Partnerships (KTPs), by Ian Gibbs (Research & Enterprise Office) (Core members).
- Week 4, 16-10-2019 (E214): Webpage development session, by Esther Mondragón (Core members).
- Week 3, 09-10-2019 (A227): Seminar, by Ernesto Jiménez-Ruiz, Michael Garcia Ortiz, Mark Broom, Laure Daviaud and Essy Mulwa.
- Week 2, 02-10-2019 (A227): Seminar, by Ed Alonso, Esther Mondragón, Constantino Carlos Reyes-Aldasoro and Giacomo Tarroni.
- Week 1, 25-09-2019 (AG02): UKRI Funding procedures and opportunities, by Peter Aggar (Research & Enterprise Office) (Core members).